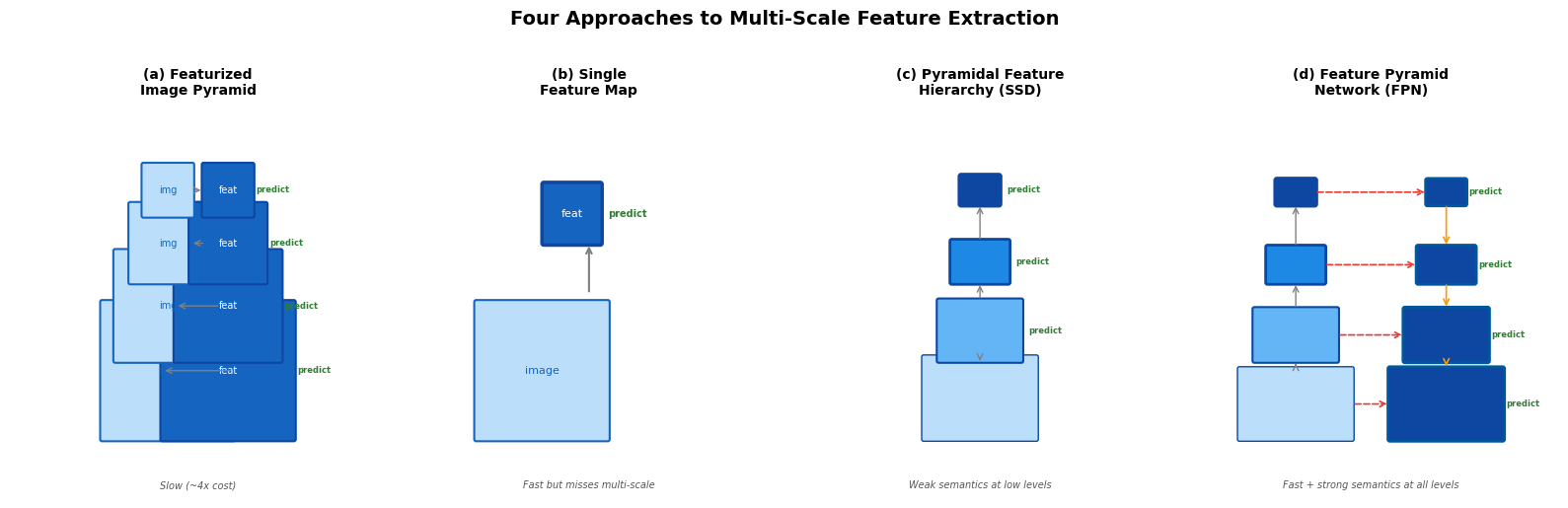
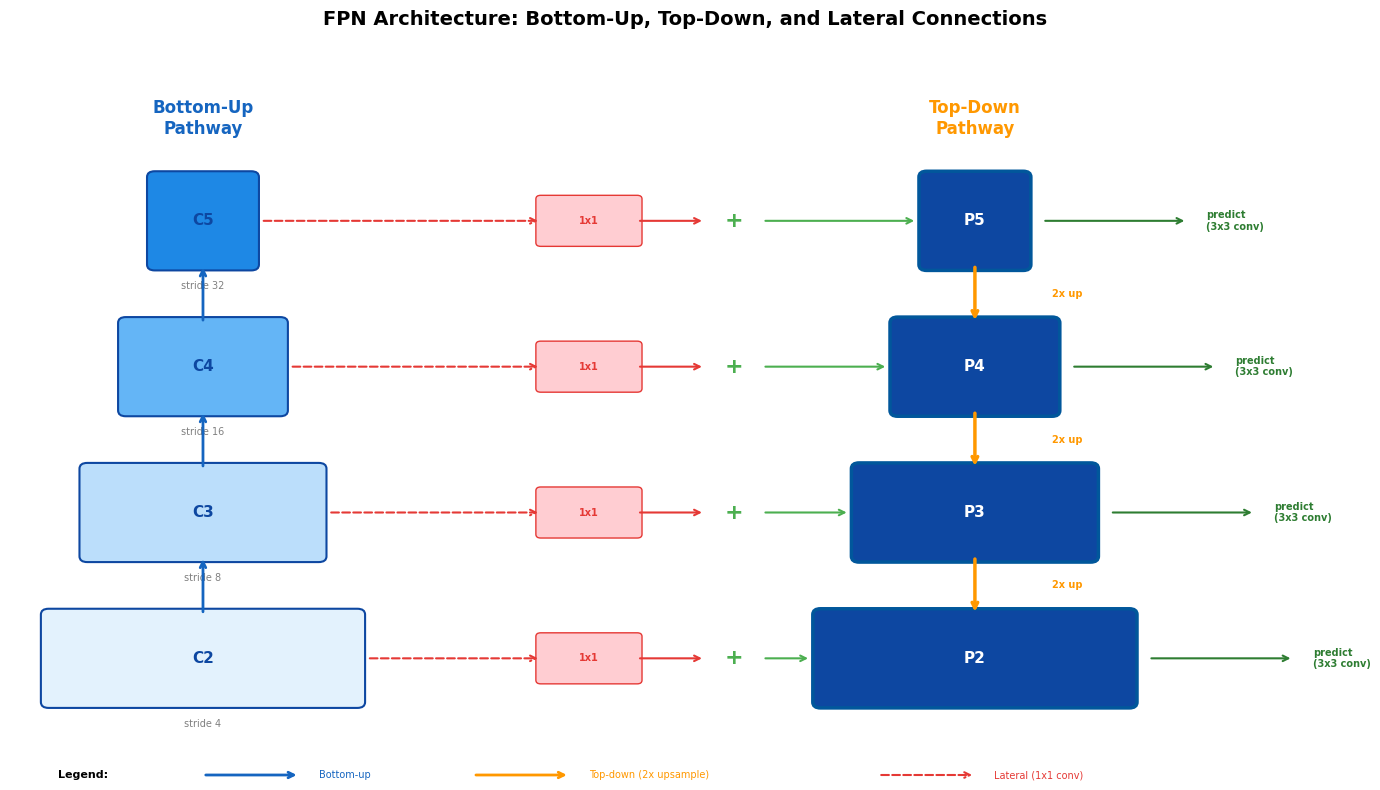
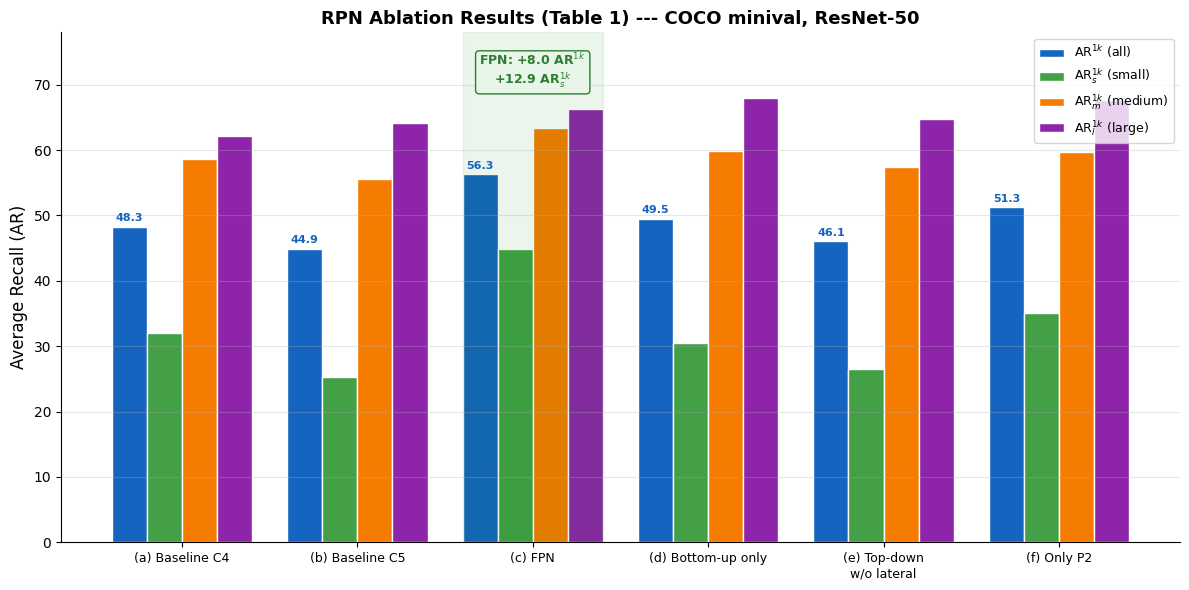
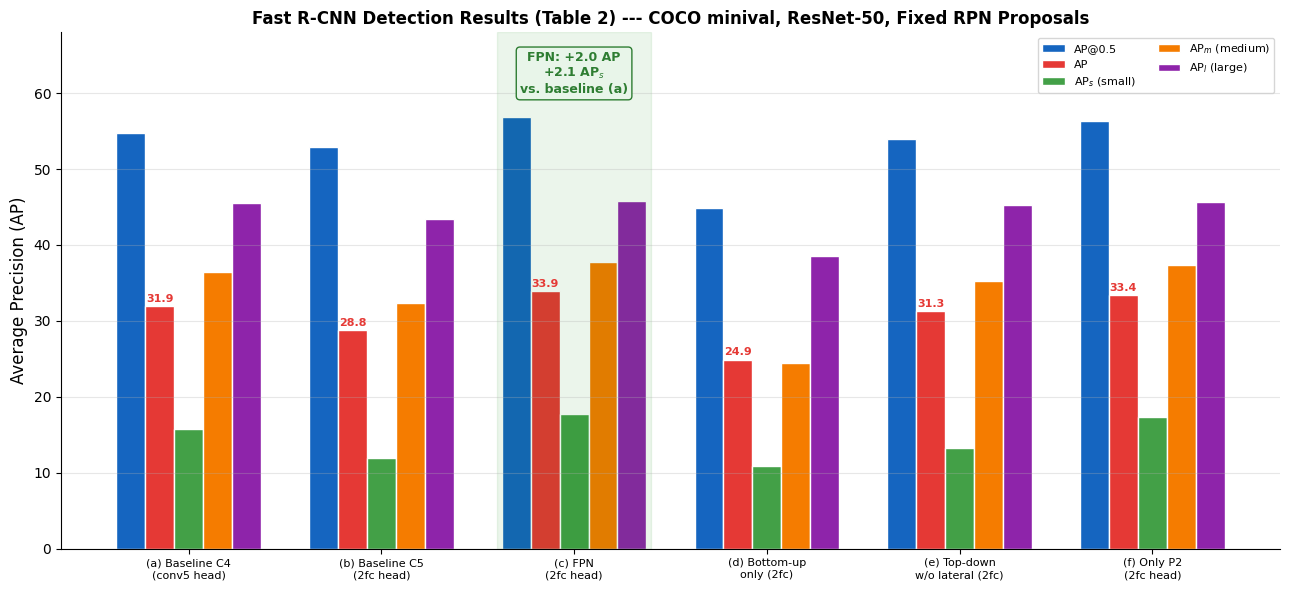
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import numpy as np
fig, ax = plt.subplots(figsize=(14, 8))
ax.set_xlim(0, 14)
ax.set_ylim(0, 10)
ax.axis('off')
ax.set_title('FPN Architecture: Bottom-Up, Top-Down, and Lateral Connections',
fontsize=14, fontweight='bold', pad=15)
# Bottom-up pathway (left side)
bu_x = 2.0
bu_levels = [
('C2', 3.2, 1.0, '#E3F2FD', 'stride 4'),
('C3', 2.4, 3.0, '#BBDEFB', 'stride 8'),
('C4', 1.6, 5.0, '#64B5F6', 'stride 16'),
('C5', 1.0, 7.0, '#1E88E5', 'stride 32'),
]
# Top-down pathway (right side)
td_x = 10.0
td_levels = [
('P2', 3.2, 1.0, '#0D47A1'),
('P3', 2.4, 3.0, '#0D47A1'),
('P4', 1.6, 5.0, '#0D47A1'),
('P5', 1.0, 7.0, '#0D47A1'),
]
# Draw bottom-up blocks
for name, w, y, color, stride in bu_levels:
x = bu_x - w/2
ax.add_patch(patches.FancyBboxPatch((x, y), w, 1.2, boxstyle='round,pad=0.08',
facecolor=color, edgecolor='#0D47A1', linewidth=1.5))
ax.text(bu_x, y+0.6, f'{name}', ha='center', va='center', fontsize=11,
fontweight='bold', color='#0D47A1')
ax.text(bu_x, y-0.3, stride, ha='center', va='center', fontsize=7, color='gray')
# Bottom-up arrows
for i in range(len(bu_levels)-1):
ax.annotate('', xy=(bu_x, bu_levels[i+1][2]), xytext=(bu_x, bu_levels[i][2]+1.2),
arrowprops=dict(arrowstyle='->', color='#1565C0', lw=2))
ax.text(bu_x, 9.0, 'Bottom-Up\nPathway', ha='center', va='center', fontsize=12,
fontweight='bold', color='#1565C0')
# Draw top-down blocks
for name, w, y, color in td_levels:
x = td_x - w/2
ax.add_patch(patches.FancyBboxPatch((x, y), w, 1.2, boxstyle='round,pad=0.08',
facecolor=color, edgecolor='#01579B', linewidth=2.5))
ax.text(td_x, y+0.6, f'{name}', ha='center', va='center', fontsize=11,
fontweight='bold', color='white')
# Top-down arrows (downward: P5 -> P4 -> P3 -> P2)
for i in range(len(td_levels)-1, 0, -1):
ax.annotate('', xy=(td_x, td_levels[i-1][2]+1.2), xytext=(td_x, td_levels[i][2]),
arrowprops=dict(arrowstyle='->', color='#FF9800', lw=2.5))
# Label the 2x upsample
mid_y = (td_levels[i][2] + td_levels[i-1][2]+1.2) / 2
ax.text(td_x + 0.8, mid_y, '2x up', fontsize=7, color='#FF9800',
fontweight='bold', va='center')
ax.text(td_x, 9.0, 'Top-Down\nPathway', ha='center', va='center', fontsize=12,
fontweight='bold', color='#FF9800')
# Lateral connections
mid_x = 6.0
for i in range(len(bu_levels)):
bu_name, bu_w, bu_y, _, _ = bu_levels[i]
td_name, td_w, td_y, _ = td_levels[i]
y_mid = bu_y + 0.6
# Arrow from bottom-up to middle (1x1 conv)
ax.annotate('', xy=(mid_x - 0.5, y_mid), xytext=(bu_x + bu_w/2 + 0.1, y_mid),
arrowprops=dict(arrowstyle='->', color='#E53935', lw=1.5, linestyle='--'))
# 1x1 conv box
ax.add_patch(patches.FancyBboxPatch((mid_x - 0.5, y_mid - 0.3), 1.0, 0.6,
boxstyle='round,pad=0.05', facecolor='#FFCDD2', edgecolor='#E53935', linewidth=1))
ax.text(mid_x, y_mid, '1x1', ha='center', va='center', fontsize=7,
fontweight='bold', color='#E53935')
# Addition symbol
add_x = mid_x + 1.5
ax.text(add_x, y_mid, '+', ha='center', va='center', fontsize=16,
fontweight='bold', color='#4CAF50')
# Arrow from 1x1 to addition
ax.annotate('', xy=(add_x - 0.3, y_mid), xytext=(mid_x + 0.5, y_mid),
arrowprops=dict(arrowstyle='->', color='#E53935', lw=1.5))
# Arrow from addition to top-down block
ax.annotate('', xy=(td_x - td_w/2 - 0.1, y_mid), xytext=(add_x + 0.3, y_mid),
arrowprops=dict(arrowstyle='->', color='#4CAF50', lw=1.5))
# Predict arrows from each P level
for name, w, y, color in td_levels:
pred_x = td_x + w/2 + 0.2
ax.annotate('', xy=(pred_x + 1.5, y+0.6), xytext=(pred_x, y+0.6),
arrowprops=dict(arrowstyle='->', color='#2E7D32', lw=1.5))
ax.text(pred_x + 1.7, y+0.6, 'predict\n(3x3 conv)', ha='left', va='center',
fontsize=7, color='#2E7D32', fontweight='bold')
# Legend
legend_y = 0.0
ax.text(0.5, legend_y, 'Legend:', fontsize=8, fontweight='bold', va='center')
ax.annotate('', xy=(3.0, legend_y), xytext=(2.0, legend_y),
arrowprops=dict(arrowstyle='->', color='#1565C0', lw=2))
ax.text(3.2, legend_y, 'Bottom-up', fontsize=7, va='center', color='#1565C0')
ax.annotate('', xy=(5.8, legend_y), xytext=(4.8, legend_y),
arrowprops=dict(arrowstyle='->', color='#FF9800', lw=2))
ax.text(6.0, legend_y, 'Top-down (2x upsample)', fontsize=7, va='center', color='#FF9800')
ax.annotate('', xy=(10.0, legend_y), xytext=(9.0, legend_y),
arrowprops=dict(arrowstyle='->', color='#E53935', lw=1.5, linestyle='--'))
ax.text(10.2, legend_y, 'Lateral (1x1 conv)', fontsize=7, va='center', color='#E53935')
plt.tight_layout()
plt.show()