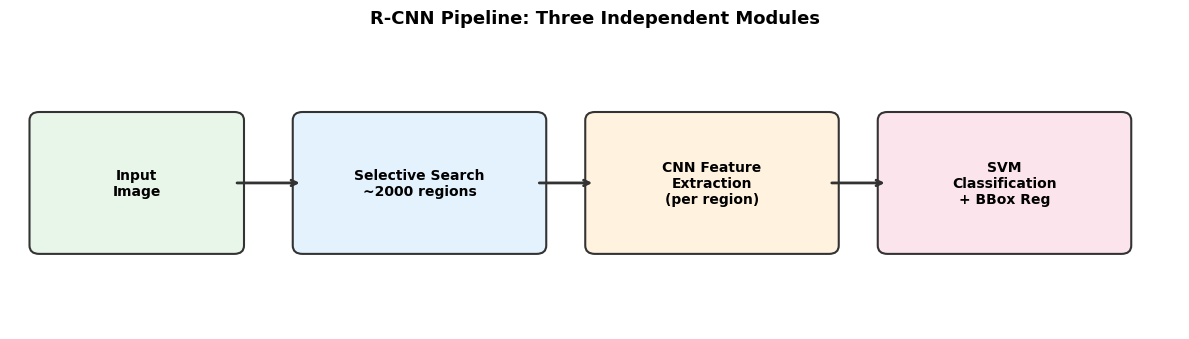
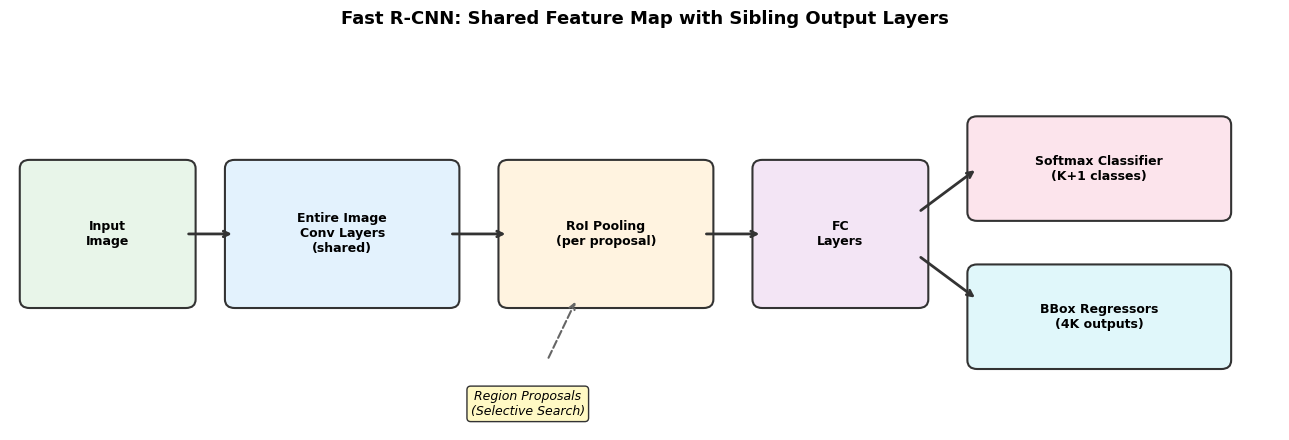
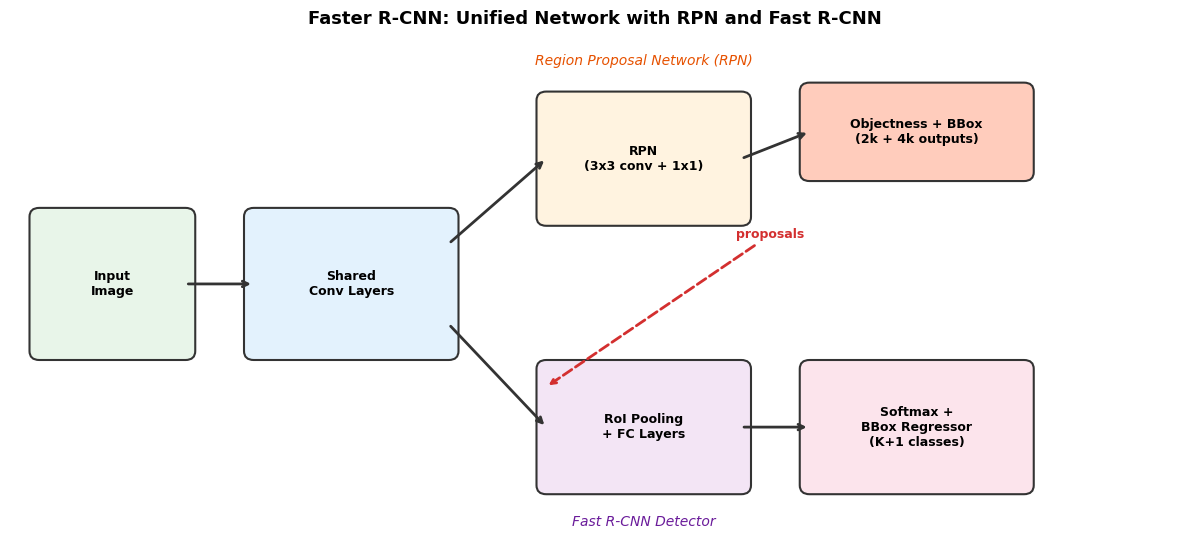
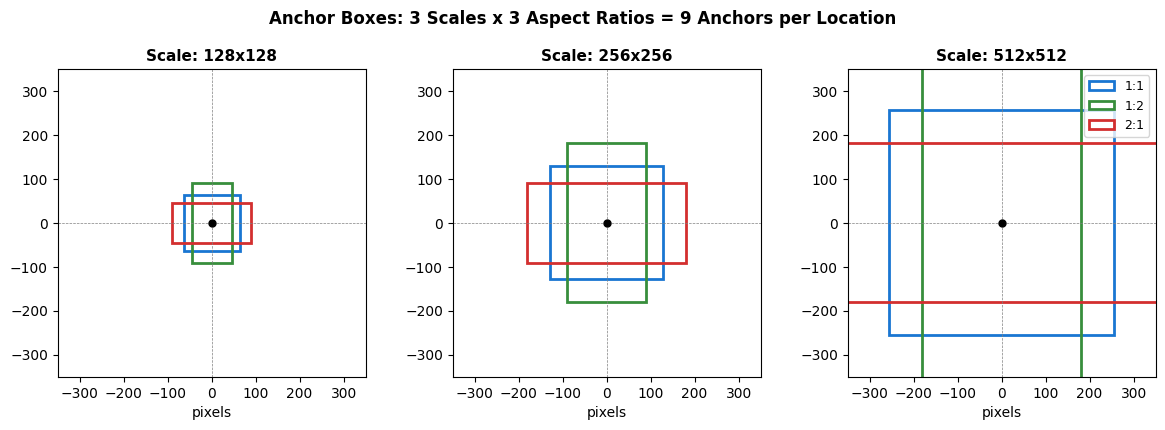
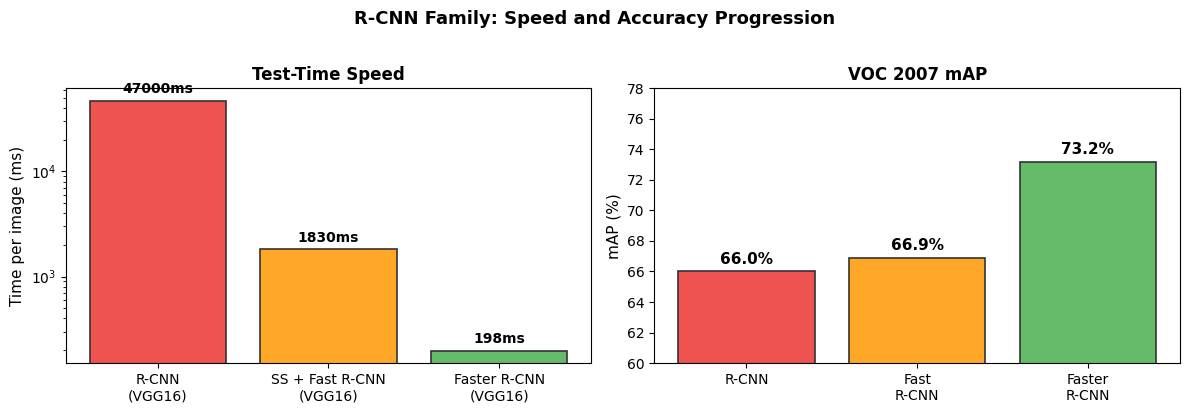
fig, ax = plt.subplots(1, 1, figsize=(12, 5.5))
ax.set_xlim(0, 12)
ax.set_ylim(0, 5.5)
ax.axis('off')
# Image and shared conv
boxes_main = [
(0.3, 2.0, 1.5, 1.5, 'Input\nImage', '#E8F5E9'),
(2.5, 2.0, 2.0, 1.5, 'Shared\nConv Layers', '#E3F2FD'),
]
# RPN branch (top)
boxes_rpn = [
(5.5, 3.5, 2.0, 1.3, 'RPN\n(3x3 conv + 1x1)', '#FFF3E0'),
(8.2, 4.0, 2.2, 0.9, 'Objectness + BBox\n(2k + 4k outputs)', '#FFCCBC'),
]
# Detection branch (bottom)
boxes_det = [
(5.5, 0.5, 2.0, 1.3, 'RoI Pooling\n+ FC Layers', '#F3E5F5'),
(8.2, 0.5, 2.2, 1.3, 'Softmax +\nBBox Regressor\n(K+1 classes)', '#FCE4EC'),
]
for x, y, w, h, text, color in boxes_main + boxes_rpn + boxes_det:
rect = mpatches.FancyBboxPatch(
(x, y), w, h, boxstyle="round,pad=0.1",
facecolor=color, edgecolor='#333333', linewidth=1.5
)
ax.add_patch(rect)
ax.text(x + w/2, y + h/2, text,
ha='center', va='center', fontsize=9, fontweight='bold')
# Arrows
arrow_style = dict(arrowstyle='->', color='#333333', lw=2)
ax.annotate('', xy=(2.5, 2.75), xytext=(1.8, 2.75), arrowprops=arrow_style)
# Shared conv to RPN
ax.annotate('', xy=(5.5, 4.15), xytext=(4.5, 3.2),
arrowprops=arrow_style)
# Shared conv to detection
ax.annotate('', xy=(5.5, 1.15), xytext=(4.5, 2.3),
arrowprops=arrow_style)
# RPN outputs
ax.annotate('', xy=(8.2, 4.45), xytext=(7.5, 4.15), arrowprops=arrow_style)
# Detection outputs
ax.annotate('', xy=(8.2, 1.15), xytext=(7.5, 1.15), arrowprops=arrow_style)
# RPN proposals feed into detection
ax.annotate('proposals', xy=(5.5, 1.6), xytext=(7.8, 3.3),
arrowprops=dict(arrowstyle='->', color='#D32F2F', lw=2, linestyle='dashed'),
fontsize=9, color='#D32F2F', fontweight='bold',
ha='center', va='center')
# Labels
ax.text(6.5, 5.2, 'Region Proposal Network (RPN)',
fontsize=10, fontstyle='italic', ha='center', color='#E65100')
ax.text(6.5, 0.05, 'Fast R-CNN Detector',
fontsize=10, fontstyle='italic', ha='center', color='#6A1B9A')
ax.set_title('Faster R-CNN: Unified Network with RPN and Fast R-CNN',
fontsize=13, fontweight='bold', pad=10)
plt.tight_layout()
plt.show()