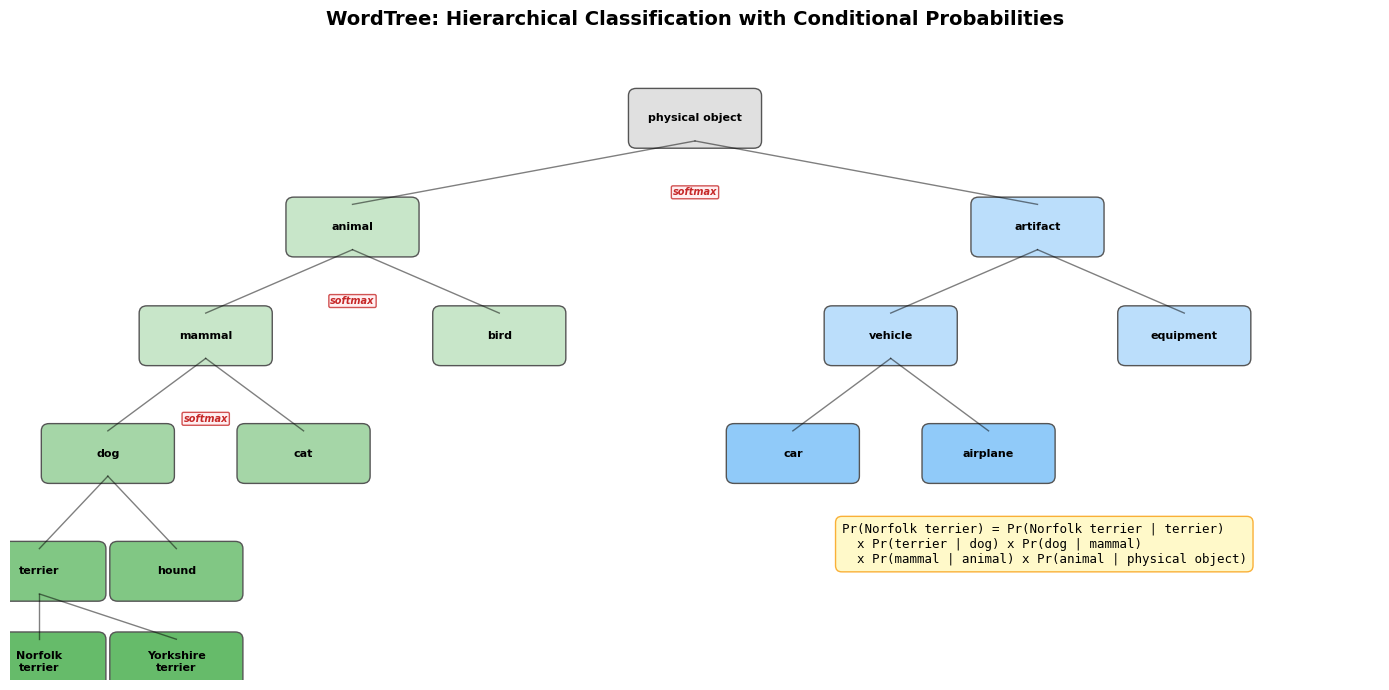
import matplotlib.pyplot as plt
import matplotlib.patches as patches
fig, ax = plt.subplots(figsize=(14, 7))
ax.set_xlim(0, 14)
ax.set_ylim(0, 7)
ax.axis('off')
ax.set_title('WordTree: Hierarchical Classification with Conditional Probabilities',
fontsize=14, fontweight='bold', pad=15)
# Tree nodes: (x, y, label, color)
nodes = [
(7, 6.2, 'physical object', '#E0E0E0'),
(3.5, 5.0, 'animal', '#C8E6C9'),
(10.5, 5.0, 'artifact', '#BBDEFB'),
(2, 3.8, 'mammal', '#C8E6C9'),
(5, 3.8, 'bird', '#C8E6C9'),
(9, 3.8, 'vehicle', '#BBDEFB'),
(12, 3.8, 'equipment', '#BBDEFB'),
(1, 2.5, 'dog', '#A5D6A7'),
(3, 2.5, 'cat', '#A5D6A7'),
(8, 2.5, 'car', '#90CAF9'),
(10, 2.5, 'airplane', '#90CAF9'),
(0.3, 1.2, 'terrier', '#81C784'),
(1.7, 1.2, 'hound', '#81C784'),
(0.3, 0.2, 'Norfolk\nterrier', '#66BB6A'),
(1.7, 0.2, 'Yorkshire\nterrier', '#66BB6A'),
]
# Draw nodes
for x, y, label, color in nodes:
rect = patches.FancyBboxPatch((x - 0.6, y - 0.25), 1.2, 0.5,
boxstyle='round,pad=0.08',
facecolor=color, edgecolor='#555555', linewidth=1)
ax.add_patch(rect)
ax.text(x, y, label, ha='center', va='center', fontsize=8, fontweight='bold')
# Draw edges
edges = [
(7, 5.95, 3.5, 5.25), (7, 5.95, 10.5, 5.25), # physical object -> animal, artifact
(3.5, 4.75, 2, 4.05), (3.5, 4.75, 5, 4.05), # animal -> mammal, bird
(10.5, 4.75, 9, 4.05), (10.5, 4.75, 12, 4.05), # artifact -> vehicle, equipment
(2, 3.55, 1, 2.75), (2, 3.55, 3, 2.75), # mammal -> dog, cat
(9, 3.55, 8, 2.75), (9, 3.55, 10, 2.75), # vehicle -> car, airplane
(1, 2.25, 0.3, 1.45), (1, 2.25, 1.7, 1.45), # dog -> terrier, hound
(0.3, 0.95, 0.3, 0.45), (0.3, 0.95, 1.7, 0.45), # terrier -> Norfolk, Yorkshire
]
for x1, y1, x2, y2 in edges:
ax.plot([x1, x2], [y1, y2], 'k-', linewidth=1, alpha=0.5)
# Softmax annotations
softmax_groups = [
(3.5, 10.5, 5.0, 'softmax'), # animal vs artifact
(2, 5, 3.8, 'softmax'), # mammal vs bird
(1, 3, 2.5, 'softmax'), # dog vs cat
]
for x1, x2, y, label in softmax_groups:
mid = (x1 + x2) / 2
ax.annotate(label, xy=(mid, y + 0.35), fontsize=7, color='#C62828',
ha='center', fontweight='bold', style='italic',
bbox=dict(boxstyle='round,pad=0.15', facecolor='#FFEBEE', edgecolor='#C62828', alpha=0.8))
# Probability computation
prob_text = (
'Pr(Norfolk terrier) = Pr(Norfolk terrier | terrier)\n'
' x Pr(terrier | dog) x Pr(dog | mammal)\n'
' x Pr(mammal | animal) x Pr(animal | physical object)'
)
ax.text(8.5, 1.5, prob_text, fontsize=9, va='center',
bbox=dict(boxstyle='round,pad=0.5', facecolor='#FFF9C4', edgecolor='#F9A825', alpha=0.9),
family='monospace')
plt.tight_layout()
plt.show()