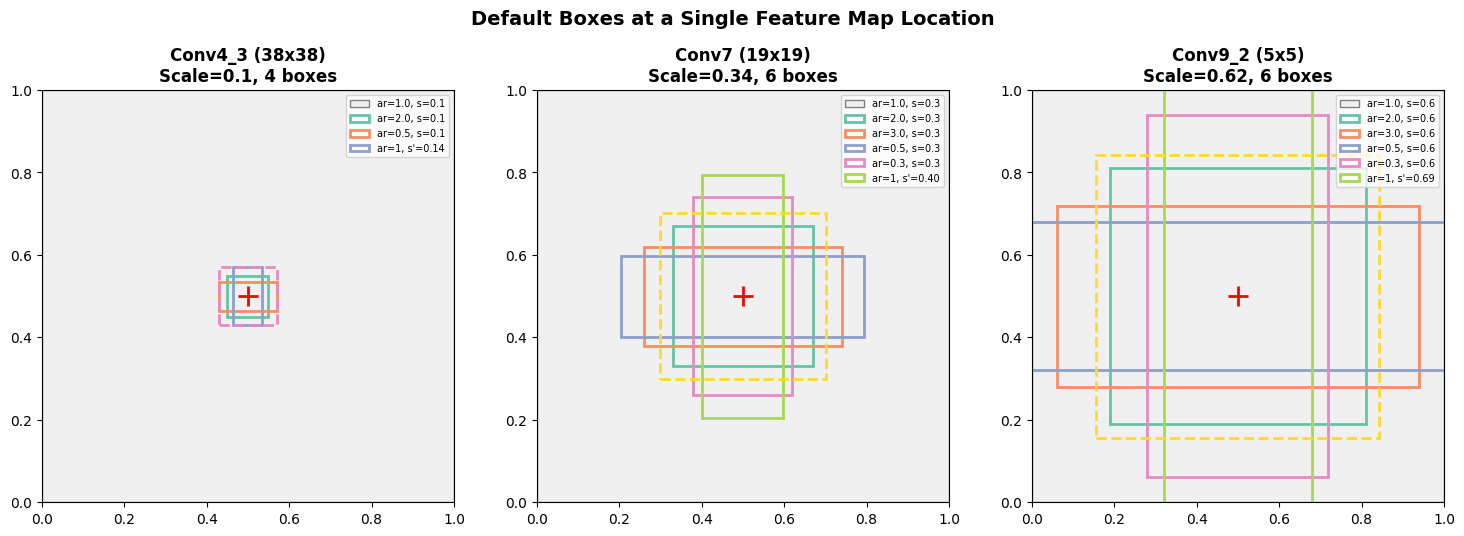
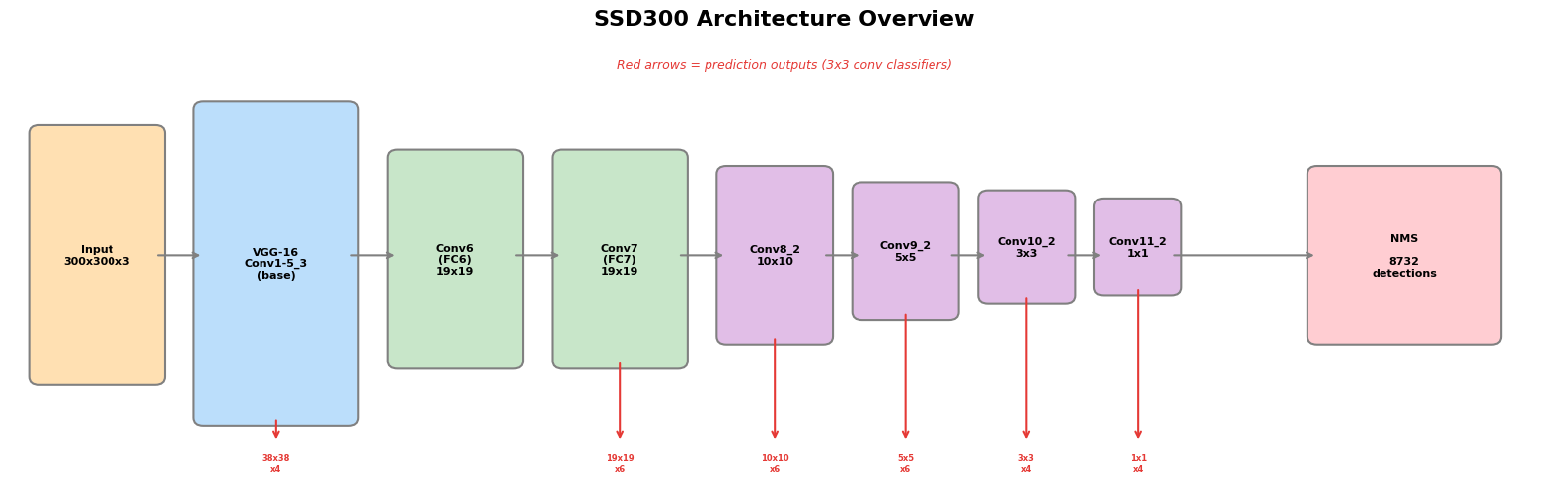
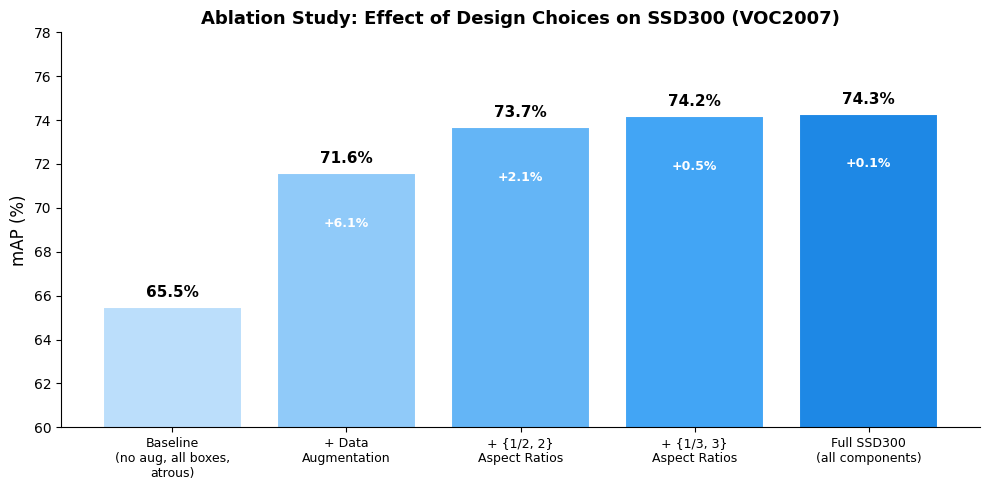
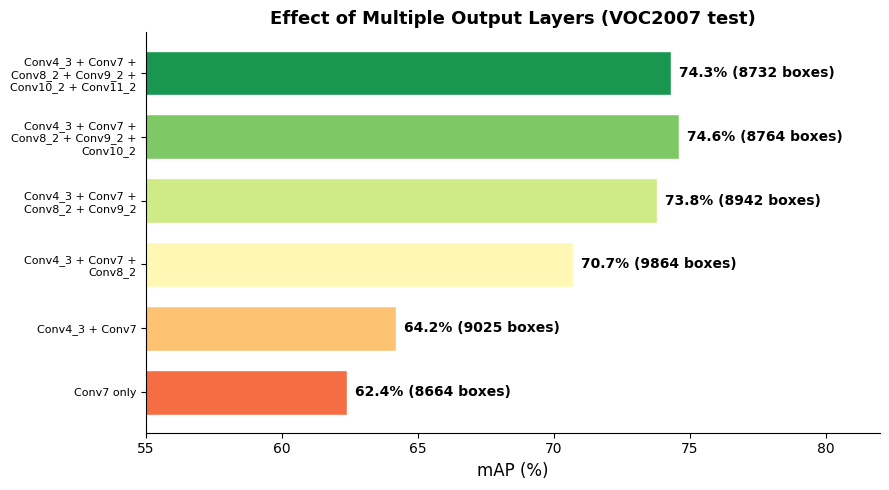
fig, ax = plt.subplots(figsize=(16, 5))
ax.set_xlim(0, 16)
ax.set_ylim(0, 5)
ax.axis('off')
ax.set_title('SSD300 Architecture Overview', fontsize=16, fontweight='bold', pad=20)
# Define blocks: (x, y, width, height, label, color)
blocks = [
(0.3, 1.0, 1.2, 3.0, 'Input\n300x300x3', '#FFE0B2'),
(2.0, 0.5, 1.5, 3.8, 'VGG-16\nConv1-5_3\n(base)', '#BBDEFB'),
(4.0, 1.2, 1.2, 2.5, 'Conv6\n(FC6)\n19x19', '#C8E6C9'),
(5.7, 1.2, 1.2, 2.5, 'Conv7\n(FC7)\n19x19', '#C8E6C9'),
(7.4, 1.5, 1.0, 2.0, 'Conv8_2\n10x10', '#E1BEE7'),
(8.8, 1.8, 0.9, 1.5, 'Conv9_2\n5x5', '#E1BEE7'),
(10.1, 2.0, 0.8, 1.2, 'Conv10_2\n3x3', '#E1BEE7'),
(11.3, 2.1, 0.7, 1.0, 'Conv11_2\n1x1', '#E1BEE7'),
(13.5, 1.5, 1.8, 2.0, 'NMS\n\n8732\ndetections', '#FFCDD2'),
]
for x, y, w, h, label, color in blocks:
ax.add_patch(patches.FancyBboxPatch((x, y), w, h, boxstyle='round,pad=0.1',
facecolor=color, edgecolor='gray', linewidth=1.5))
ax.text(x + w/2, y + h/2, label, ha='center', va='center', fontsize=8, fontweight='bold')
# Arrows between blocks
arrow_style = dict(arrowstyle='->', color='gray', lw=1.5)
connections = [
(1.5, 2.5, 2.0, 2.5),
(3.5, 2.5, 4.0, 2.5),
(5.2, 2.5, 5.7, 2.5),
(6.9, 2.5, 7.4, 2.5),
(8.4, 2.5, 8.8, 2.5),
(9.7, 2.5, 10.1, 2.5),
(10.9, 2.5, 11.3, 2.5),
]
for x1, y1, x2, y2 in connections:
ax.annotate('', xy=(x2, y2), xytext=(x1, y1), arrowprops=arrow_style)
# Prediction arrows (downward from detection layers)
pred_layers = [
(2.75, 0.5, '38x38\nx4'), # Conv4_3
(6.3, 1.2, '19x19\nx6'), # Conv7
(7.9, 1.5, '10x10\nx6'), # Conv8_2
(9.25, 1.8, '5x5\nx6'), # Conv9_2
(10.5, 2.0, '3x3\nx4'), # Conv10_2
(11.65, 2.1, '1x1\nx4'), # Conv11_2
]
for x, y_start, label in pred_layers:
ax.annotate('', xy=(x, 0.2), xytext=(x, y_start),
arrowprops=dict(arrowstyle='->', color='#E53935', lw=1.5))
ax.text(x, 0.05, label, ha='center', va='top', fontsize=6, color='#E53935', fontweight='bold')
# Arrow from last pred layer area to NMS
ax.annotate('', xy=(13.5, 2.5), xytext=(12.0, 2.5),
arrowprops=dict(arrowstyle='->', color='gray', lw=1.5))
ax.text(8.0, 4.8, 'Red arrows = prediction outputs (3x3 conv classifiers)', fontsize=9,
ha='center', color='#E53935', style='italic')
plt.tight_layout()
plt.show()