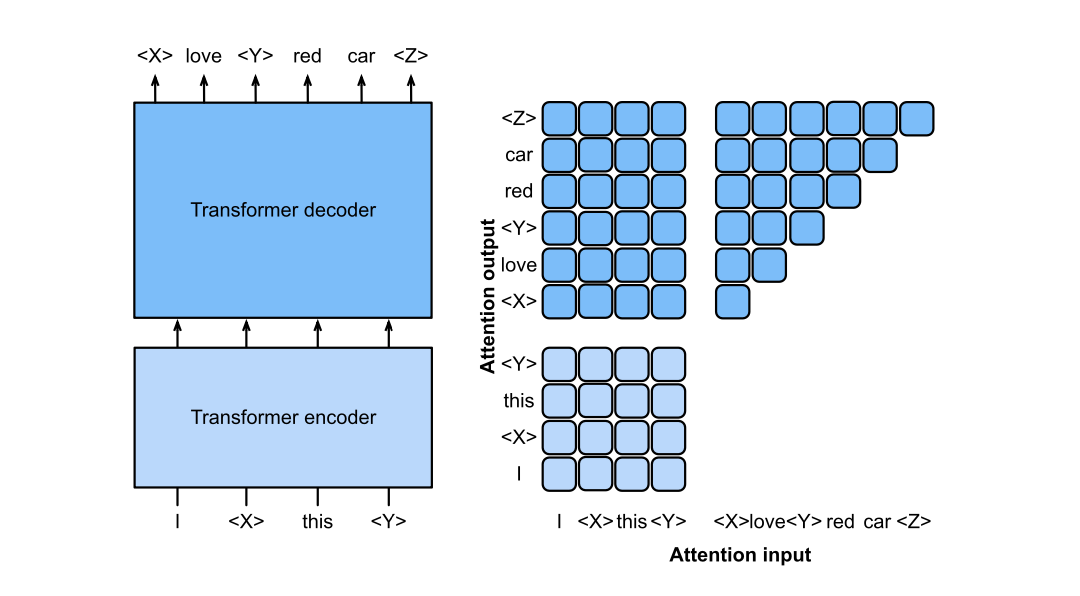
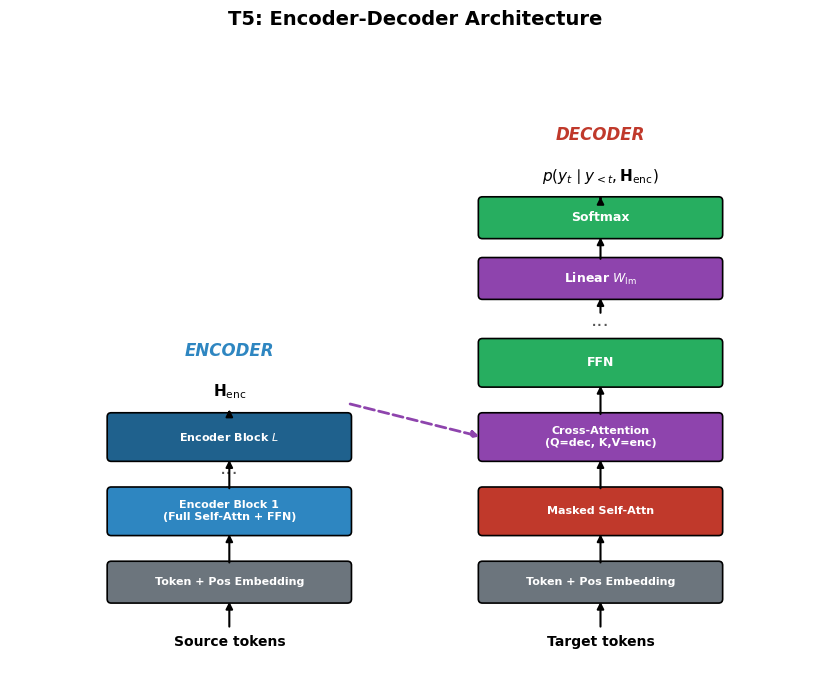
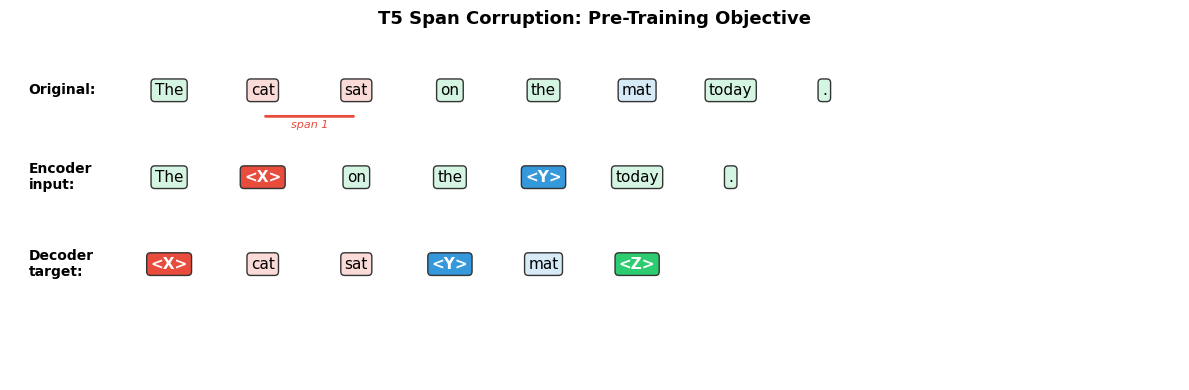
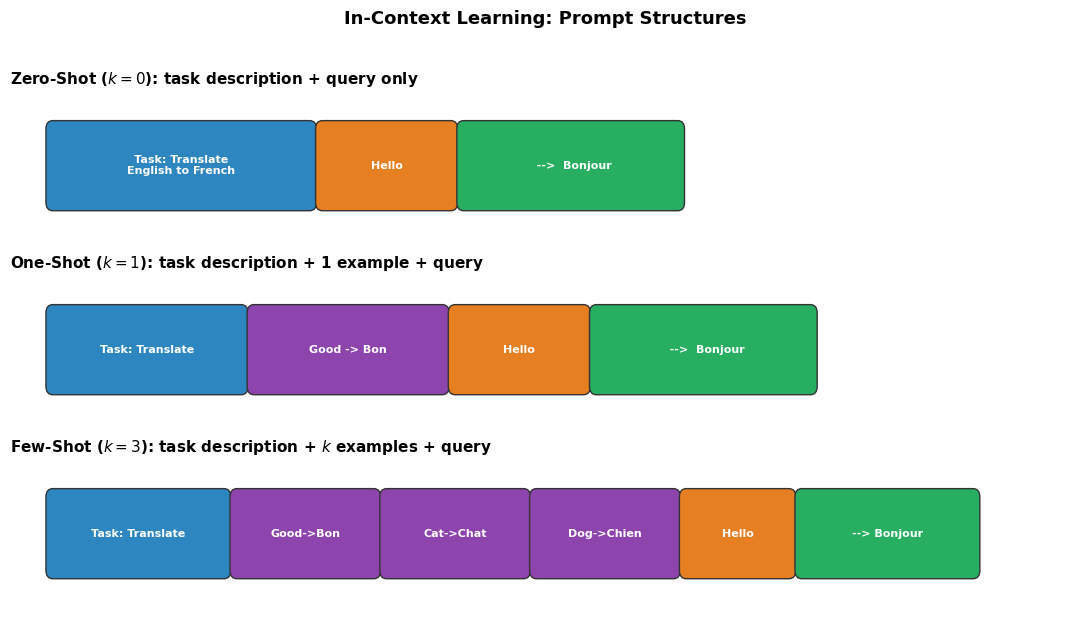
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
def draw_box(ax, xy, w, h, text, color="#4A90D9", fontsize=9, text_color="white"):
rect = mpatches.FancyBboxPatch(xy, w, h, boxstyle="round,pad=0.06",
facecolor=color, edgecolor="black", linewidth=1.2)
ax.add_patch(rect)
ax.text(xy[0] + w/2, xy[1] + h/2, text, ha="center", va="center",
fontsize=fontsize, fontweight="bold", color=text_color)
def draw_arrow(ax, start, end):
ax.annotate("", xy=end, xytext=start,
arrowprops=dict(arrowstyle="-|>", color="black", lw=1.5))
# --- T5 Encoder-Decoder Architecture ---
fig, ax = plt.subplots(figsize=(10, 7))
ax.set_xlim(-1, 11)
ax.set_ylim(-0.5, 9)
ax.set_aspect("equal")
ax.axis("off")
ax.set_title("T5: Encoder-Decoder Architecture", fontsize=14, fontweight="bold", pad=10)
# Encoder side
enc_x = 0.5
bw = 3.5
ax.text(enc_x + bw/2, 0.0, "Source tokens", ha="center", fontsize=10, fontweight="bold")
draw_box(ax, (enc_x, 0.7), bw, 0.5, "Token + Pos Embedding", color="#6C757D", fontsize=8)
draw_arrow(ax, (enc_x + bw/2, 0.25), (enc_x + bw/2, 0.7))
draw_box(ax, (enc_x, 1.7), bw, 0.6, "Encoder Block 1\n(Full Self-Attn + FFN)", color="#2E86C1", fontsize=8)
draw_arrow(ax, (enc_x + bw/2, 1.2), (enc_x + bw/2, 1.7))
draw_box(ax, (enc_x, 2.8), bw, 0.6, "Encoder Block $L$", color="#1F618D", fontsize=8)
ax.text(enc_x + bw/2, 2.55, "...", ha="center", fontsize=14, color="#555")
draw_arrow(ax, (enc_x + bw/2, 2.3), (enc_x + bw/2, 2.8))
ax.text(enc_x + bw/2, 3.7, r"$\mathbf{H}_{\rm enc}$", ha="center", fontsize=11, fontweight="bold")
draw_arrow(ax, (enc_x + bw/2, 3.4), (enc_x + bw/2, 3.55))
# Decoder side
dec_x = 6.0
ax.text(dec_x + bw/2, 0.0, "Target tokens", ha="center", fontsize=10, fontweight="bold")
draw_box(ax, (dec_x, 0.7), bw, 0.5, "Token + Pos Embedding", color="#6C757D", fontsize=8)
draw_arrow(ax, (dec_x + bw/2, 0.25), (dec_x + bw/2, 0.7))
draw_box(ax, (dec_x, 1.7), bw, 0.6, "Masked Self-Attn", color="#C0392B", fontsize=8)
draw_arrow(ax, (dec_x + bw/2, 1.2), (dec_x + bw/2, 1.7))
draw_box(ax, (dec_x, 2.8), bw, 0.6, "Cross-Attention\n(Q=dec, K,V=enc)", color="#8E44AD", fontsize=8)
draw_arrow(ax, (dec_x + bw/2, 2.3), (dec_x + bw/2, 2.8))
# Cross-attention arrow from encoder
ax.annotate("", xy=(dec_x, 3.1), xytext=(enc_x + bw, 3.6),
arrowprops=dict(arrowstyle="-|>", color="#8E44AD", lw=2, ls="--"))
draw_box(ax, (dec_x, 3.9), bw, 0.6, "FFN", color="#27AE60", fontsize=9)
draw_arrow(ax, (dec_x + bw/2, 3.4), (dec_x + bw/2, 3.9))
ax.text(dec_x + bw/2, 4.75, "...", ha="center", fontsize=14, color="#555")
draw_box(ax, (dec_x, 5.2), bw, 0.5, r"Linear $W_{\rm lm}$", color="#8E44AD", fontsize=9)
draw_arrow(ax, (dec_x + bw/2, 4.9), (dec_x + bw/2, 5.2))
draw_box(ax, (dec_x, 6.1), bw, 0.5, "Softmax", color="#27AE60", fontsize=9)
draw_arrow(ax, (dec_x + bw/2, 5.7), (dec_x + bw/2, 6.1))
ax.text(dec_x + bw/2, 6.9, r"$p(y_t \mid y_{<t}, \mathbf{H}_{\rm enc})$",
ha="center", fontsize=11, fontweight="bold")
draw_arrow(ax, (dec_x + bw/2, 6.6), (dec_x + bw/2, 6.7))
# Labels
ax.text(enc_x + bw/2, 4.3, "ENCODER", ha="center", fontsize=12,
fontweight="bold", color="#2E86C1", style="italic")
ax.text(dec_x + bw/2, 7.5, "DECODER", ha="center", fontsize=12,
fontweight="bold", color="#C0392B", style="italic")
fig.tight_layout()
plt.show()