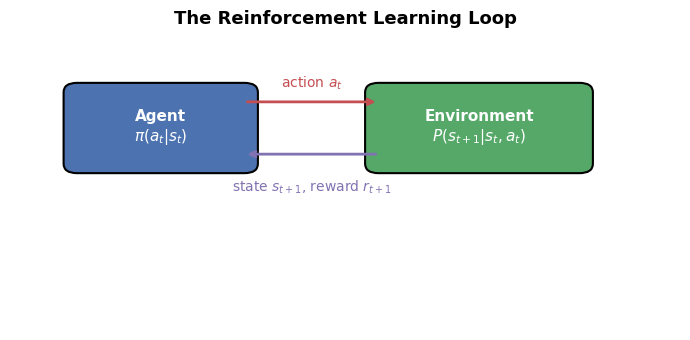
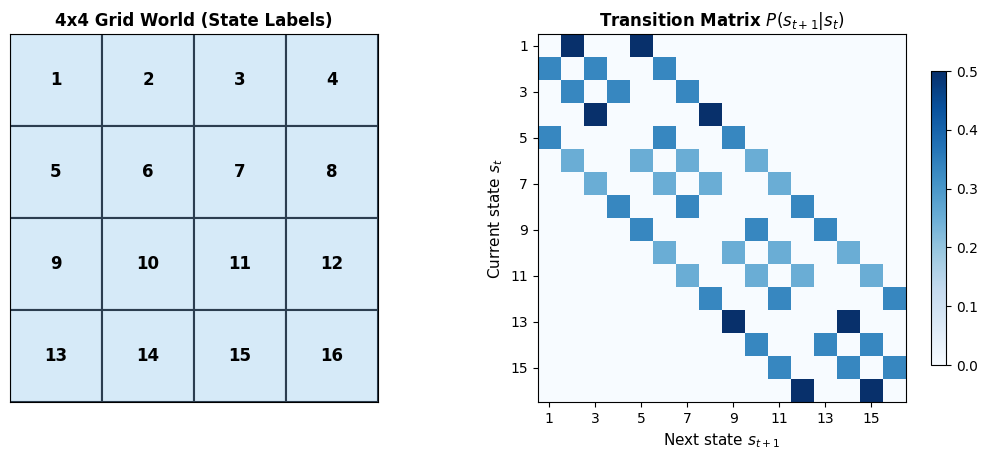
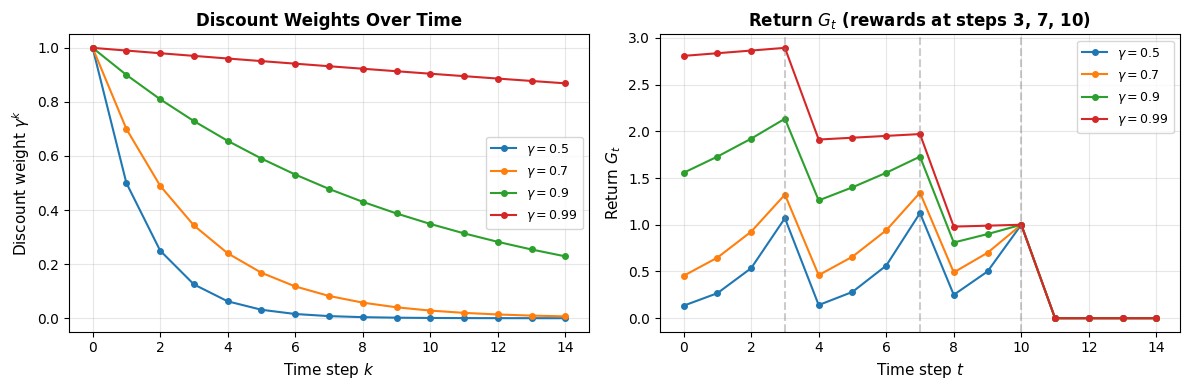
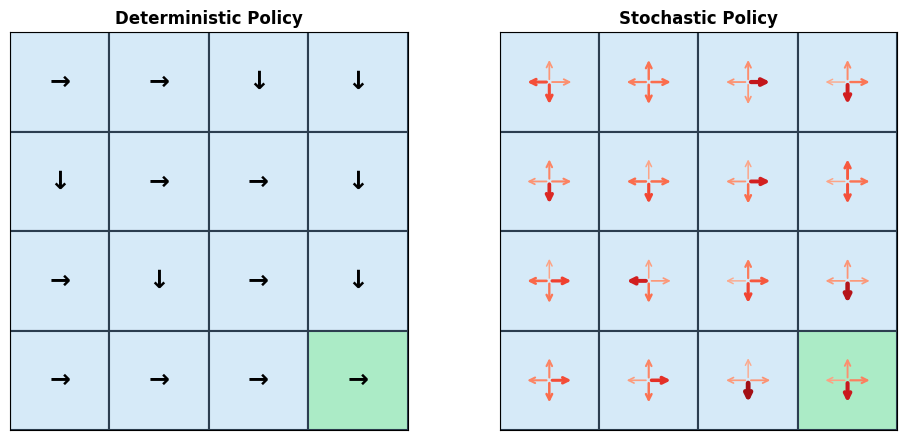
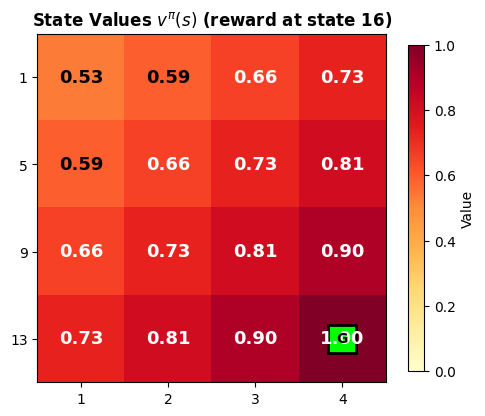
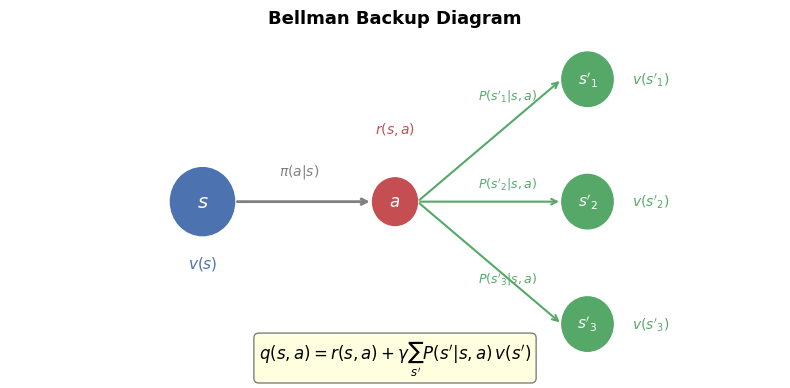
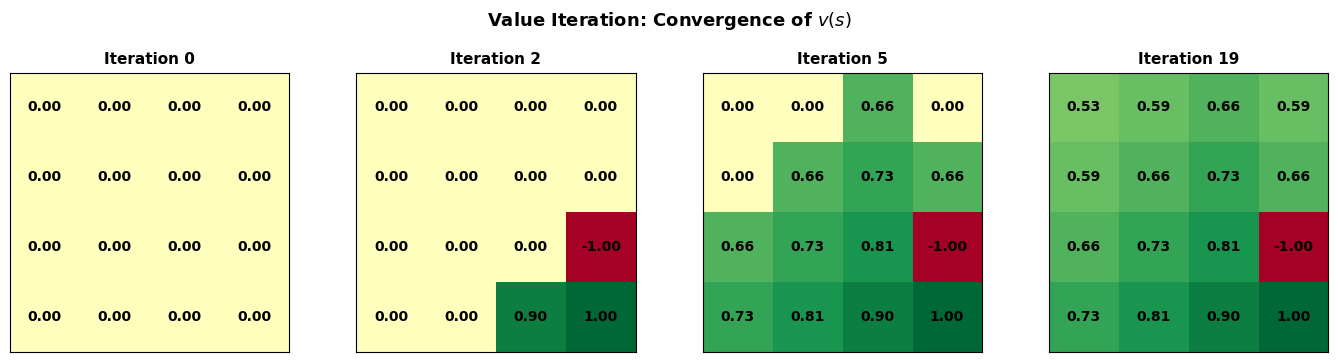
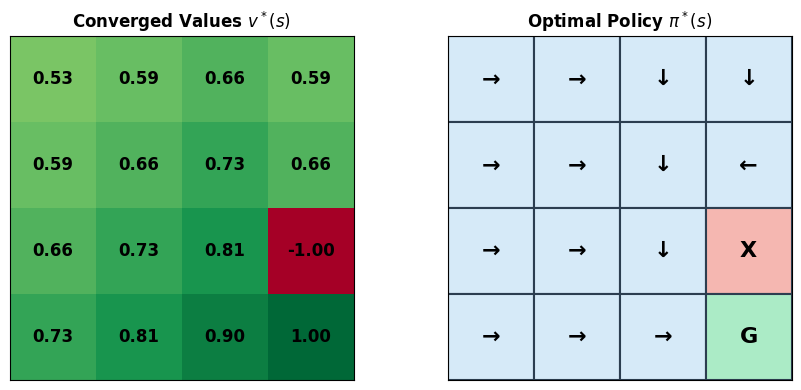
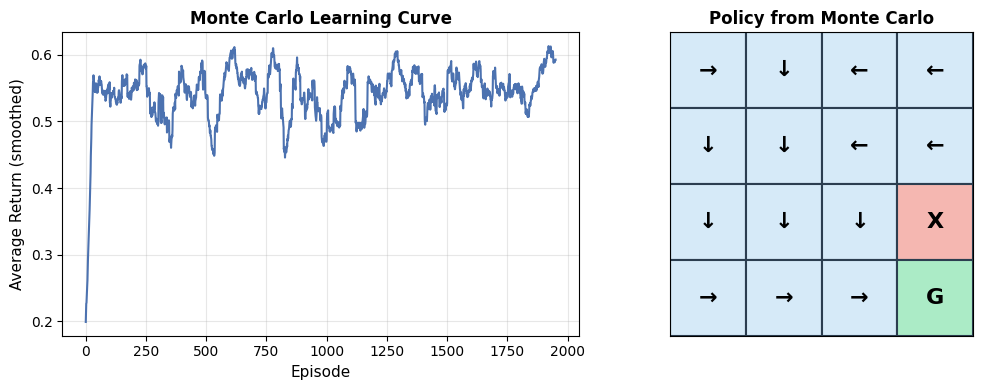
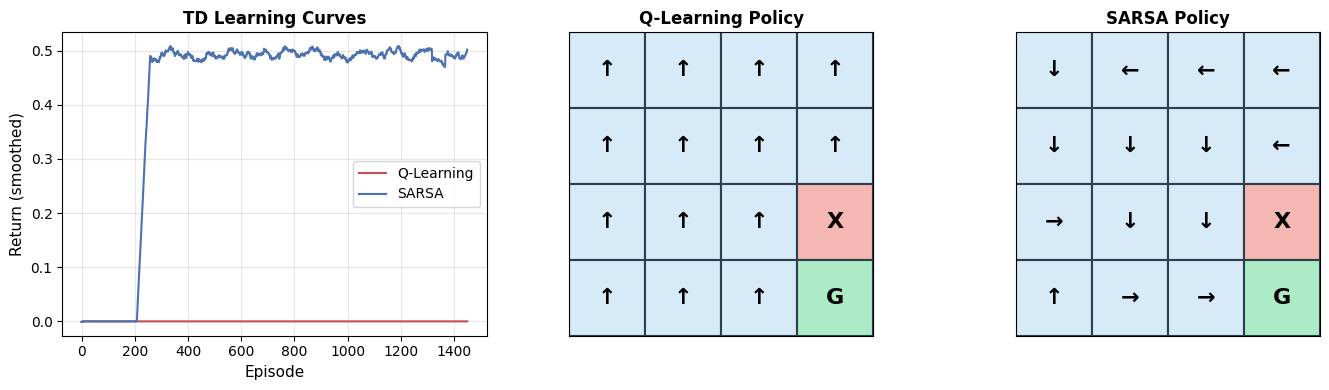
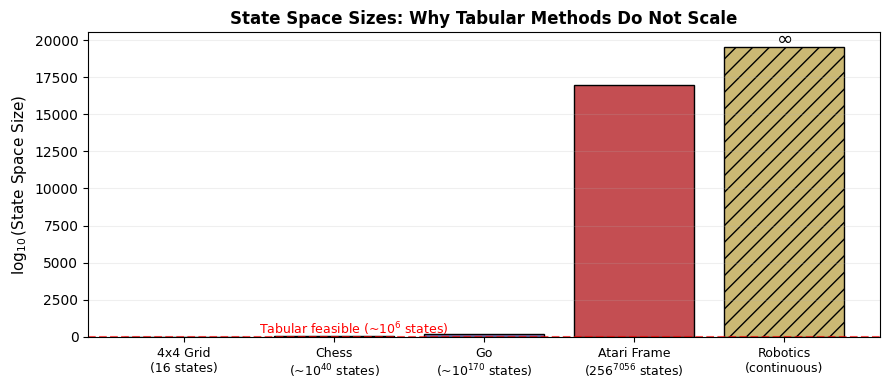
# Illustrate the Bellman backup: how v(s) depends on v(s') for successor states
fig, ax = plt.subplots(1, 1, figsize=(8, 4))
ax.set_xlim(-1, 11)
ax.set_ylim(-0.5, 4.5)
ax.axis('off')
# Central state
center_x, center_y = 2, 2
circle_s = plt.Circle((center_x, center_y), 0.5, color='#4C72B0', zorder=5)
ax.add_patch(circle_s)
ax.text(center_x, center_y, '$s$', ha='center', va='center', fontsize=14,
color='white', fontweight='bold', zorder=6)
ax.text(center_x, center_y - 0.9, '$v(s)$', ha='center', va='center', fontsize=11, color='#4C72B0')
# Action node
action_x, action_y = 5, 2
circle_a = plt.Circle((action_x, action_y), 0.35, color='#C44E52', zorder=5)
ax.add_patch(circle_a)
ax.text(action_x, action_y, '$a$', ha='center', va='center', fontsize=12,
color='white', fontweight='bold', zorder=6)
# Arrow from s to a
ax.annotate('', xy=(action_x - 0.35, action_y), xytext=(center_x + 0.5, center_y),
arrowprops=dict(arrowstyle='->', lw=2, color='gray'))
ax.text(3.5, 2.4, '$\\pi(a|s)$', ha='center', fontsize=10, color='gray')
# Successor states
successors = [(8, 3.8, "$s'_1$"), (8, 2.0, "$s'_2$"), (8, 0.2, "$s'_3$")]
for sx, sy, label in successors:
circle_sp = plt.Circle((sx, sy), 0.4, color='#55A868', zorder=5)
ax.add_patch(circle_sp)
ax.text(sx, sy, label, ha='center', va='center', fontsize=11,
color='white', fontweight='bold', zorder=6)
ax.annotate('', xy=(sx - 0.4, sy), xytext=(action_x + 0.35, action_y),
arrowprops=dict(arrowstyle='->', lw=1.5, color='#55A868'))
# Labels
ax.text(6.3, 3.5, '$P(s\'_1|s,a)$', fontsize=9, color='#55A868')
ax.text(6.3, 2.2, '$P(s\'_2|s,a)$', fontsize=9, color='#55A868')
ax.text(6.3, 0.8, '$P(s\'_3|s,a)$', fontsize=9, color='#55A868')
# Reward label
ax.text(5, 3.0, '$r(s,a)$', ha='center', fontsize=10, color='#C44E52')
# Value labels for successors
for sx, sy, label in successors:
vlabel = label.replace("s'", "v(s'").rstrip('$') + ')$'
ax.text(sx + 0.7, sy, vlabel, ha='left', va='center', fontsize=10, color='#55A868')
# Equation
ax.text(5, -0.3, "$q(s,a) = r(s,a) + \\gamma \\sum_{s'} P(s'|s,a) \\, v(s')$",
ha='center', fontsize=12, style='italic',
bbox=dict(boxstyle='round,pad=0.3', facecolor='lightyellow', edgecolor='gray'))
ax.set_title('Bellman Backup Diagram', fontsize=13, fontweight='bold')
plt.tight_layout()
plt.show()