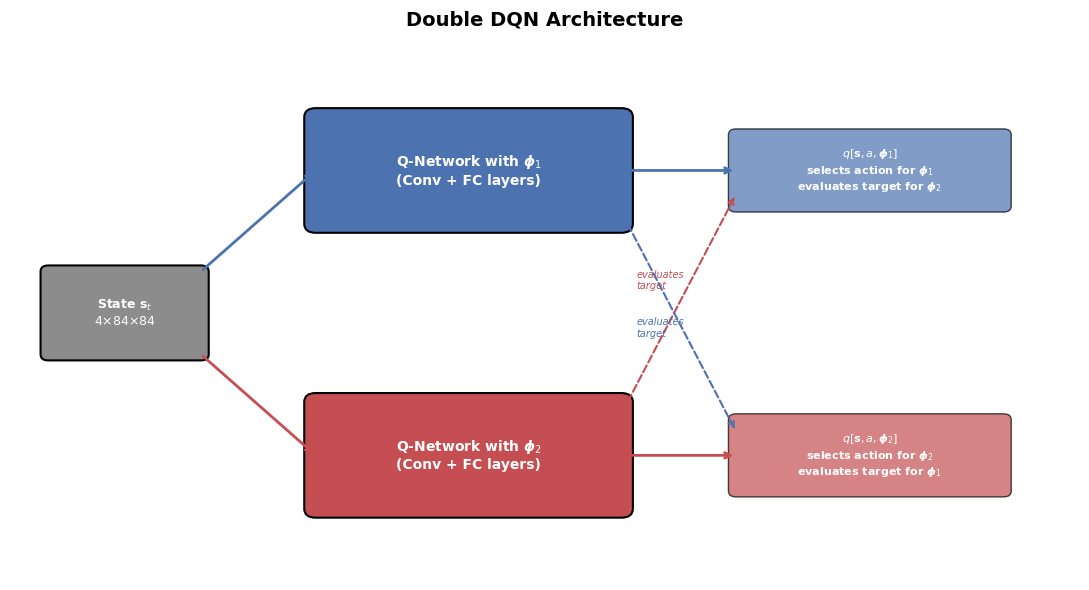
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
fig, ax = plt.subplots(1, 1, figsize=(11, 6))
ax.set_xlim(0, 14)
ax.set_ylim(0, 9)
ax.axis('off')
ax.set_title('Double DQN Architecture', fontsize=14, fontweight='bold', pad=15)
# --- Shared input ---
inp_box = mpatches.FancyBboxPatch(
(0.5, 3.8), 2.0, 1.4, boxstyle='round,pad=0.1',
facecolor='#8C8C8C', edgecolor='black', linewidth=1.5
)
ax.add_patch(inp_box)
ax.text(1.5, 4.5, 'State $\\mathbf{s}_t$\n$4{\\times}84{\\times}84$',
ha='center', va='center', fontsize=9, color='white', fontweight='bold')
# --- Network 1 (phi_1) ---
net1_box = mpatches.FancyBboxPatch(
(4.0, 6.0), 4.0, 1.8, boxstyle='round,pad=0.15',
facecolor='#4C72B0', edgecolor='black', linewidth=1.5
)
ax.add_patch(net1_box)
ax.text(6.0, 6.9, 'Q-Network with $\\boldsymbol{\\phi}_1$\n(Conv + FC layers)',
ha='center', va='center', fontsize=10, color='white', fontweight='bold')
# --- Network 2 (phi_2) ---
net2_box = mpatches.FancyBboxPatch(
(4.0, 1.2), 4.0, 1.8, boxstyle='round,pad=0.15',
facecolor='#C44E52', edgecolor='black', linewidth=1.5
)
ax.add_patch(net2_box)
ax.text(6.0, 2.1, 'Q-Network with $\\boldsymbol{\\phi}_2$\n(Conv + FC layers)',
ha='center', va='center', fontsize=10, color='white', fontweight='bold')
# --- Output 1 ---
out1_box = mpatches.FancyBboxPatch(
(9.5, 6.3), 3.5, 1.2, boxstyle='round,pad=0.1',
facecolor='#4C72B0', edgecolor='black', linewidth=1, alpha=0.7
)
ax.add_patch(out1_box)
ax.text(11.25, 6.9, '$q[\\mathbf{s}, a, \\boldsymbol{\\phi}_1]$\nselects action for $\\boldsymbol{\\phi}_1$\nevaluates target for $\\boldsymbol{\\phi}_2$',
ha='center', va='center', fontsize=8, color='white', fontweight='bold')
# --- Output 2 ---
out2_box = mpatches.FancyBboxPatch(
(9.5, 1.5), 3.5, 1.2, boxstyle='round,pad=0.1',
facecolor='#C44E52', edgecolor='black', linewidth=1, alpha=0.7
)
ax.add_patch(out2_box)
ax.text(11.25, 2.1, '$q[\\mathbf{s}, a, \\boldsymbol{\\phi}_2]$\nselects action for $\\boldsymbol{\\phi}_2$\nevaluates target for $\\boldsymbol{\\phi}_1$',
ha='center', va='center', fontsize=8, color='white', fontweight='bold')
# --- Arrows: input -> networks ---
ax.annotate('', xy=(4.0, 6.9), xytext=(2.5, 5.2),
arrowprops=dict(arrowstyle='->', lw=2, color='#4C72B0'))
ax.annotate('', xy=(4.0, 2.1), xytext=(2.5, 3.8),
arrowprops=dict(arrowstyle='->', lw=2, color='#C44E52'))
# --- Arrows: networks -> outputs ---
ax.annotate('', xy=(9.5, 6.9), xytext=(8.0, 6.9),
arrowprops=dict(arrowstyle='->', lw=2, color='#4C72B0'))
ax.annotate('', xy=(9.5, 2.1), xytext=(8.0, 2.1),
arrowprops=dict(arrowstyle='->', lw=2, color='#C44E52'))
# --- Cross arrows (evaluation) ---
ax.annotate('', xy=(9.5, 6.5), xytext=(8.0, 2.8),
arrowprops=dict(arrowstyle='->', lw=1.5, color='#C44E52',
linestyle='dashed'))
ax.text(8.2, 4.9, 'evaluates\ntarget', ha='left', fontsize=7, color='#C44E52',
fontstyle='italic')
ax.annotate('', xy=(9.5, 2.5), xytext=(8.0, 6.2),
arrowprops=dict(arrowstyle='->', lw=1.5, color='#4C72B0',
linestyle='dashed'))
ax.text(8.2, 4.1, 'evaluates\ntarget', ha='left', fontsize=7, color='#4C72B0',
fontstyle='italic')
plt.tight_layout()
plt.show()