import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
def draw_box(ax, xy, w, h, text, color="#4A90D9", fontsize=9, text_color="white"):
rect = mpatches.FancyBboxPatch(xy, w, h, boxstyle="round,pad=0.06",
facecolor=color, edgecolor="black", linewidth=1.2)
ax.add_patch(rect)
ax.text(xy[0] + w/2, xy[1] + h/2, text, ha="center", va="center",
fontsize=fontsize, fontweight="bold", color=text_color)
def draw_arrow(ax, start, end):
ax.annotate("", xy=end, xytext=start,
arrowprops=dict(arrowstyle="-|>", color="black", lw=1.5))
def draw_curved_arrow(ax, start, end, connectionstyle="arc3,rad=0.4"):
ax.annotate("", xy=end, xytext=start,
arrowprops=dict(arrowstyle="-|>", color="#C0392B", lw=1.5, ls="--",
connectionstyle=connectionstyle))
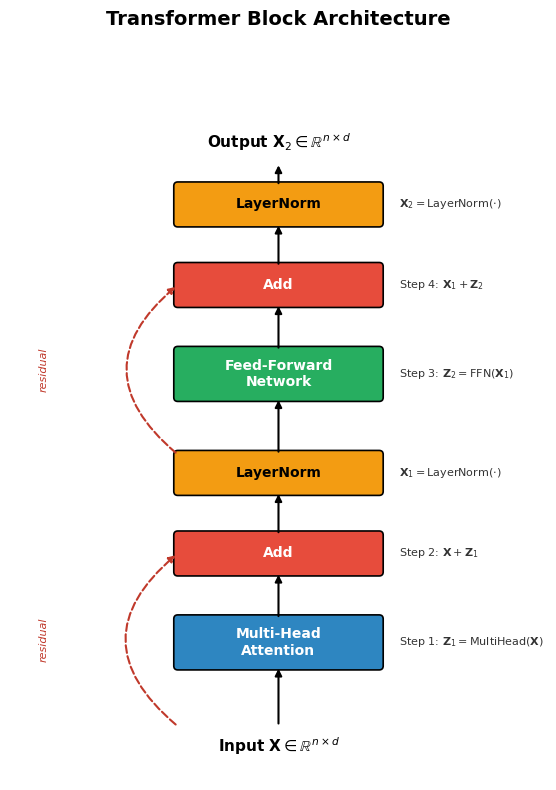
# --- Transformer Block Architecture Diagram ---
fig, ax = plt.subplots(figsize=(6, 8))
ax.set_xlim(-1, 7)
ax.set_ylim(-0.5, 10.5)
ax.set_aspect("equal")
ax.axis("off")
ax.set_title("Transformer Block Architecture", fontsize=14, fontweight="bold", pad=12)
cx = 1.5 # center x for main blocks
bw = 3.0 # block width
# Input
ax.text(cx + bw/2, 0.0, r"Input $\mathbf{X} \in \mathbb{R}^{n \times d}$",
ha="center", va="center", fontsize=11, fontweight="bold")
# Multi-Head Attention
y_mha = 1.2
draw_box(ax, (cx, y_mha), bw, 0.7, "Multi-Head\nAttention", color="#2E86C1", fontsize=10)
draw_arrow(ax, (cx + bw/2, 0.3), (cx + bw/2, y_mha))
# Add (residual)
y_add1 = 2.6
draw_box(ax, (cx, y_add1), bw, 0.55, "Add", color="#E74C3C", fontsize=10)
draw_arrow(ax, (cx + bw/2, y_mha + 0.7), (cx + bw/2, y_add1))
# Residual arrow
draw_curved_arrow(ax, (cx, 0.3), (cx, y_add1 + 0.275), connectionstyle="arc3,rad=-0.6")
ax.text(-0.5, (0.3 + y_add1 + 0.275)/2, "residual", fontsize=8, color="#C0392B",
ha="center", va="center", rotation=90, style="italic")
# LayerNorm 1
y_ln1 = 3.8
draw_box(ax, (cx, y_ln1), bw, 0.55, "LayerNorm", color="#F39C12", fontsize=10, text_color="black")
draw_arrow(ax, (cx + bw/2, y_add1 + 0.55), (cx + bw/2, y_ln1))
# FFN
y_ffn = 5.2
draw_box(ax, (cx, y_ffn), bw, 0.7, "Feed-Forward\nNetwork", color="#27AE60", fontsize=10)
draw_arrow(ax, (cx + bw/2, y_ln1 + 0.55), (cx + bw/2, y_ffn))
# Add (residual) 2
y_add2 = 6.6
draw_box(ax, (cx, y_add2), bw, 0.55, "Add", color="#E74C3C", fontsize=10)
draw_arrow(ax, (cx + bw/2, y_ffn + 0.7), (cx + bw/2, y_add2))
# Residual arrow
draw_curved_arrow(ax, (cx, y_ln1 + 0.55), (cx, y_add2 + 0.275), connectionstyle="arc3,rad=-0.6")
ax.text(-0.5, (y_ln1 + 0.55 + y_add2 + 0.275)/2, "residual", fontsize=8, color="#C0392B",
ha="center", va="center", rotation=90, style="italic")
# LayerNorm 2
y_ln2 = 7.8
draw_box(ax, (cx, y_ln2), bw, 0.55, "LayerNorm", color="#F39C12", fontsize=10, text_color="black")
draw_arrow(ax, (cx + bw/2, y_add2 + 0.55), (cx + bw/2, y_ln2))
# Output
ax.text(cx + bw/2, 9.0, r"Output $\mathbf{X}_2 \in \mathbb{R}^{n \times d}$",
ha="center", va="center", fontsize=11, fontweight="bold")
draw_arrow(ax, (cx + bw/2, y_ln2 + 0.55), (cx + bw/2, 8.7))
# Step labels on the right
annotations = [
(y_mha + 0.35, "Step 1: $\\mathbf{Z}_1 = \\mathrm{MultiHead}(\\mathbf{X})$"),
(y_add1 + 0.275, "Step 2: $\\mathbf{X} + \\mathbf{Z}_1$"),
(y_ln1 + 0.275, "$\\mathbf{X}_1 = \\mathrm{LayerNorm}(\\cdot)$"),
(y_ffn + 0.35, "Step 3: $\\mathbf{Z}_2 = \\mathrm{FFN}(\\mathbf{X}_1)$"),
(y_add2 + 0.275, "Step 4: $\\mathbf{X}_1 + \\mathbf{Z}_2$"),
(y_ln2 + 0.275, "$\\mathbf{X}_2 = \\mathrm{LayerNorm}(\\cdot)$"),
]
for y, txt in annotations:
ax.text(cx + bw + 0.3, y, txt, fontsize=8, va="center", color="#333")
fig.tight_layout()
plt.show()